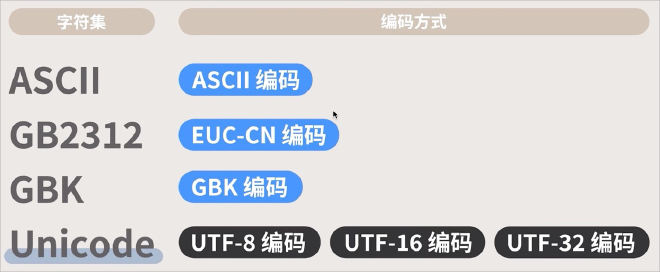
字符编码(ASCII、GBK、UTF-8、Unicode等)和字体

Table of Contents
参考:
- top level: 锟斤拷�⊠是怎样炼成的——中文显示“⼊”门指南
- lower level: 一听就懂字符集、ASCII、GBK、UTF-8、Unicode、乱码、字符编码、解码问题的讲解
top level 视频的稿子在这里: 锟斤拷�⊠是怎样炼成的——中文显示“⼊”门指南 文字版脚本
综述 #
计算机只认识0,1二进制编码。电脑显示文字,涉及到三个重要的概念:字符、字符集,和字符编码(编码方式)。
字符编码,类似索引,根据字符编码显示字符集里对应的字符。类似下图这样:

需要注意的是,码位和索引不是一个东西!由于[[字符编码(ASCII、GBK、UTF-8、Unicode等)#UTF-8码位变长原理]]这个东西的存在,也就意味着码位和索引不是线性关系!

乱码原因 #
假设一个场景,就很好理解了。
我在电脑上保存了一份UTF-8编码的文档,内容如下:
今天中午吃什么?
输出如下:
\\\\xE4\\\\xBB\\\\x8A\\\\xE5\\\\xA4\\\\xA9\\\\xE4\\\\xB8\\\\xAD\\\\xE5\\\\x8D\\\\x88\\\\xE5\\\\x90\\\\x83\\\\xE4\\\\xBB\\\\x80\\\\xE4\\\\xB9\\\\x88\\\\xEF\\\\xBC\\\\x9F
可以看到码位为两个字节。
如果输入为英文呢?
hello
输出如下:
\\\\x68\\\\x65\\\\x6C\\\\x6C\\\\x6F
可以看到码位为一个字节(编码格式可以理解为同ASCII)。
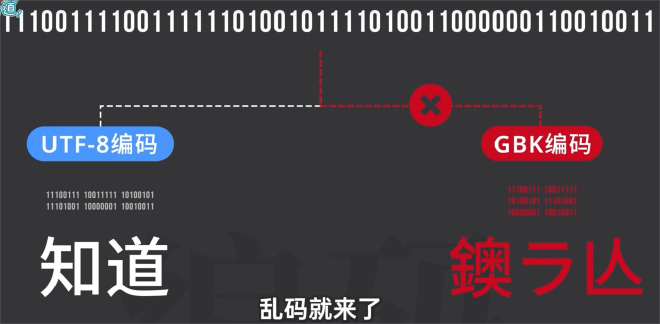
如果我保存的今天中午吃什么?的文档,被理解为ASCII文档,用ASCII编码来打开呢?那么输出肯定就是乱码。
锟斤拷 #
当 GBK 与 Unicode 激情碰撞之后,噩梦般的上古神器——“锟(kūn)斤拷”就诞生了。 你看啊,当你写出这段文字,点击保存,此时它们就被按照 GBK 编码存储成了这串二进制数字。 然后你把这份文档发给了心爱的人,她用最常见的 UTF-8 编码打开。此时软件就懵逼了,因为它会发现这些东西根本无法正常显示。 此时,Unicode 就会用这个替换符号�,来展示所有无法正确显示的字符。 这时她也懵逼了~心想算了,保存一下发给室友让她帮忙打开吧。在她点击保存的那一瞬间,文档中所有的�字符,就被根据 UTF-8 编码,编码为了 0xEF BF BD。 而收到这份文件的大冤种室友,再次使用 GBK 编码打开了这份文档。此时根据 GBK 编码规则,如果有连续两个问号,那么 EFBF、BDEF、BFBD 这三个码位对应的,正是“锟斤拷”三个字。也就是说,连续两个问号,就对应了一个“锟斤拷”,一串问号,就对应了满屏的“锟斤拷”。 经过这套行云流水的操作,你的爱已经完全找不回来了,坍缩成了无穷无尽的“锟斤拷”。
UTF-8码位变长原理 #
UTF-8码位字节长度不定的原理是:拿码位的前几个比特来作为标志位,比如00,01,10,11。00代表后面两个字节是一个码位,01代表后面3个字节是一个码位,10代表4个字节,11代表5个字节这样。(P.S. 现在想起来原理好简单,以前还想了好久🤣)
参考[[字符编码(ASCII、GBK、UTF-8、Unicode等)#乱码原因]]这里举的例子。
Emoji 冷知识 #
由于 Unicode 只规定 emoji 的含义,不管它们具体长啥样,所以决定你看到的 emoji 长啥样的,是字体。
字体与字符编码的关系 #
字符是一个抽象的概念,在计算机上是以字符编码的形式来存储的,是字符在计算中的代号,但具体要如何在屏幕上显示,并没有做规定,如果要在屏幕上显示对应的文字,仅仅靠字符编码是不够的,还需要字体文件。
字体规定了字符如何显示,在字体文件中,包含了其支持的字符的显示信息。
一个字体文件包含一个或者多个字符映射表(Charmap),它的作用就是把一个字符从它的字符编码映射到字形索引,即该字符在字体文件中的位置。字符映射表一般使用 Unicode 作为字形的编码。
一般一个字符的渲染步骤为:
- 加载字体文件;
- 确定要输出的字体大小;
- 输入这个字符的编码值;
- 根据字体文件里面的字符映射表,把编码值转换成字形索引;
- 根据索引从字体中加载这个字形;
- 将这个字形渲染成位图,有可能进行加粗、倾斜等变换。
在选择字符映射表时,如果和输入的字符编码不一样,输出的字形要么是错的,要么就根本找不到对应的字形,屏幕上就会显示一个方块字。